Wouldn’t it be amazing if machines could be able to think like us and learn some stuff like cooking, playing some sports, responding to phone calls all by themselves? Well we are actually heading in that direction and future is probably not that far. This particular field of research comes under the umbrella of Reinforcement Learning (RL). RL is amazing because using this approach we can actually program some self learning behaviors into machines and let them learn anything by trying and gaining experience. In this article to give an idea about how we can program such “self learning machines”, I am going to explain how we can train some matchboxes to play Tic-tac-toe with human level performance just by playing a few games with them. Moreover, we will extend this idea further and write a tic-tac-toe program in python that learns how to play the game by playing thousands of games with itself within a few seconds.
Matchbox Educable Naughts and Crosses Engine: MENACE
So, the approach that I am going to explain is based on something called MENACE proposed by Donald Michie in 1961. Using this approach we can train a set of matchboxes to play tic-tac-toe by playing several games with them. After each game they will get smarter and smarter and after some point they will become undefeatable. The basic idea is this: MENACE consisted of a matchbox for each possible game position, each matchbox containing a number of colored beads, a different color for each possible move from that position. By drawing a bead at random from the matchbox corresponding to the current game position, one could determine MENACE’s move. When a game was over, beads were added to or removed from the boxes used during play to reinforce or punish MENACE’s decisions [1]. Did you get it? Don’t worry. Let’s see this idea in detail.
Setting up everything
- For each configuration of the tic-tac-toe game, we have to have a matchbox. The number of match box required can be very large as the number of possible “game states” is a large number (\(3^9 = 19683\)). However, this number can be reduced this if we apply the fact that some game states will never appear if the winning state comes before that and some game states we dont have to count (i.e when the board is fully covered). To read more about this state reduction you can refer to this article: brianshourd.com.
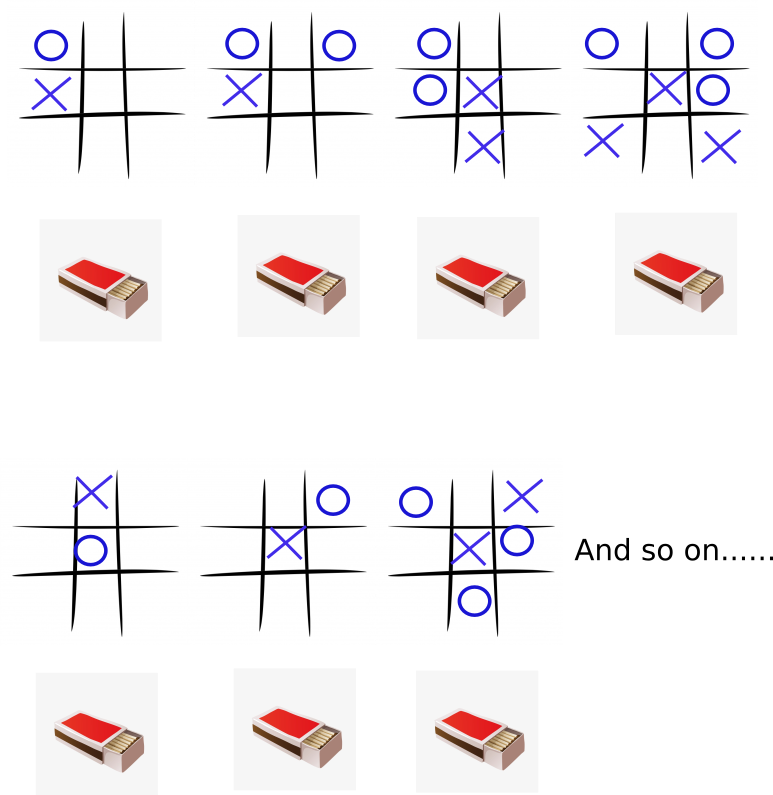
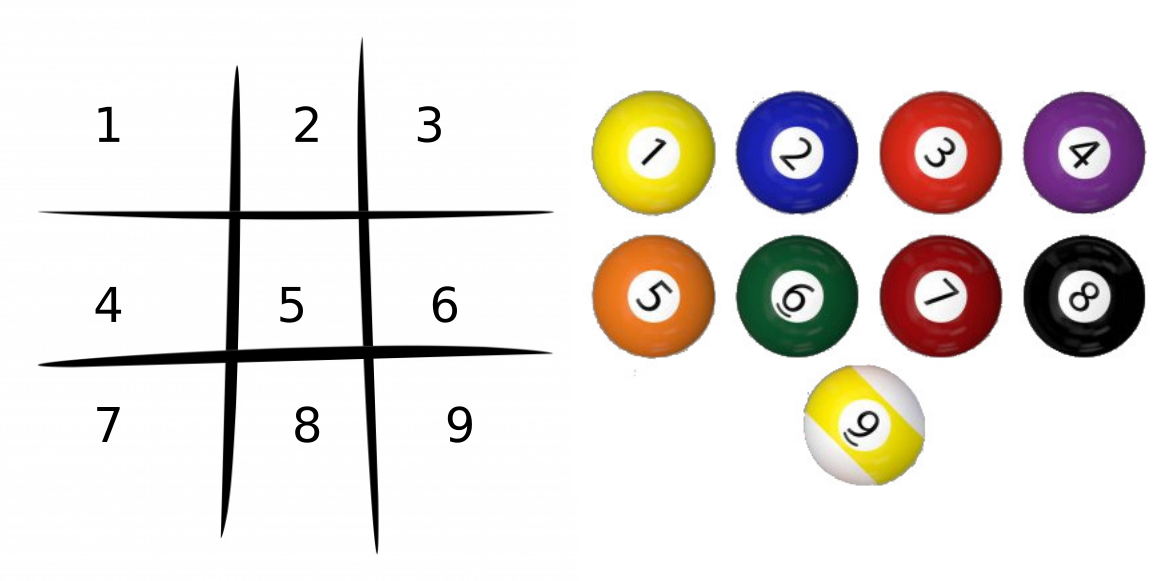
- Once we have the matchboxes, we will throw away the match sticks and put some beads of 9 different colors. Each colour should have more or less equal number of beads inside the box and this number should be high (say 10 beads of each color). Each color will represent a unique box on the board as shown below.
The game play
Assuming that the matchboxes will play first, the game play and updating of the beads will be done as follows:
-
We will pick the matchbox corresponding to the initial state of the game (i.e matchbox corresponds to the empty board). Then we will randomly pick a bead from the matchbox. According to the color of the bead, we will place a cross in the corresponding box of the board. And thus matchbox has played its turn. We will keep that matchbox aside and write down in a paper which color we has picked from that matchbox.
-
Now its your turn. You place your zero wherever you want.
-
Now it’s matchboxes turn again. Again pick the matchbox corresponding to the board configuration. Open it and randomly pick a bead. Put a cross on the board according to the color of the bead. Note down the color you picked from that matchbox and keep the matchbox aside.
-
Repeat this process again from step 2 until the game ends.
-
-
If you win: We have to remove one bead from each of the matchboxes we just used. The color of the beads should be same as the one we picked from that matchbox in that particular game. We punish the matchboxes that way for losing the game.
-
If matchboxes win: We have to add one bead to each of the matchboxes we just used. The color of the beads should be same as the one we picked from that matchbox in that particular game. We reward them this way for winning!!
-
If the game is draw (tie) : No need to do anything.
-
And with this one iteration of the training process ends. Our matchboxes are now a bit smarter then before. We have to repeat the process again and again till on the winning rate of the match boxes reaches a desired level.
Why it works
I think if you have read the article to this point then you have probably understood why matchboxes will eventually start winning or drawing the games. If you didn’t get it then also it’s absolutely fine. Because I am going to explain it anyway. Initially there will be very low probability that the matchboxes will win a game against you. This is because there will be more or less equal probability of picking a bead of specific color from the matchboxes. Because the number of beads corresponding to each color is same. As a result, it will be similar to playing random crosses against you at the beginning. Now once you start adding beads whenever matchboxes win, the probability of picking those beads will be higher from those specific matchboxes. In simple words, chances of selecting winning moves from the matchboxes will be more now. Same is the case when matchboxes lose a game; we remove the beads we picked in that game from the matchboxes. This way probability of picking the beads of those colors (losing moves) from those specific matchboxes will be reduced. If we continue the process several times the matchboxes will have more winning and drawing beads then the losing beads. And thus they will start either winning or drawing the game.
Did anyone actually try this with matchboxes?
Yes. You can check this video:
Let’s implement the strategy in python
Couple of years back I implemented this strategy in python when I did not really know about reinforcement learning. Instead of matchboxes I used lists. At first, I generated all the states and stored them in a python list. Corresponding to each state also stored a list of number between 0 to 8. Let’s call it states-moves list. These numbers are our “beads” or “moves” corresponding to the states. Then I wrote a loop to implement the self-play between two game agents so that thousands of game can be played within a few seconds. However, both the game agents use the same “states-moves” list and update it according to the strategy discussed above. And voila!! it did not work. But why?
-
Firstly, the number of states I generated was too high. That slowed down the state search loops in the program. I resolved this issue by removing duplicate states using the fact that the board is symmetric. And this made the program super fast.
-
There was no “reward” to winning the game in smallest number of moves. And since both the agents were updating the same “states-moves” list. It is actually slightly tricky to come out of self-reinforcing bad behaviors (like winning towards the end of the game even if there are chances of winning the game before). In fact, since we pick the beads randomly, it is less likely to select a winning move when there are other possible moves available. To give a push to select moves such that the game ends as quickly as possible, I added a new reward. I add more winning moves for the winning agent if the game length is short. On the other hand, for the losing agent, I remove more corresponding moves if the game length is short.
And again voila!! It worked perfectly this time. The program stores the final “states-moves” list in a file called experience.dat. Whenever it has to play with human it just loads the list from the file and play moves by sampling moves from the list.
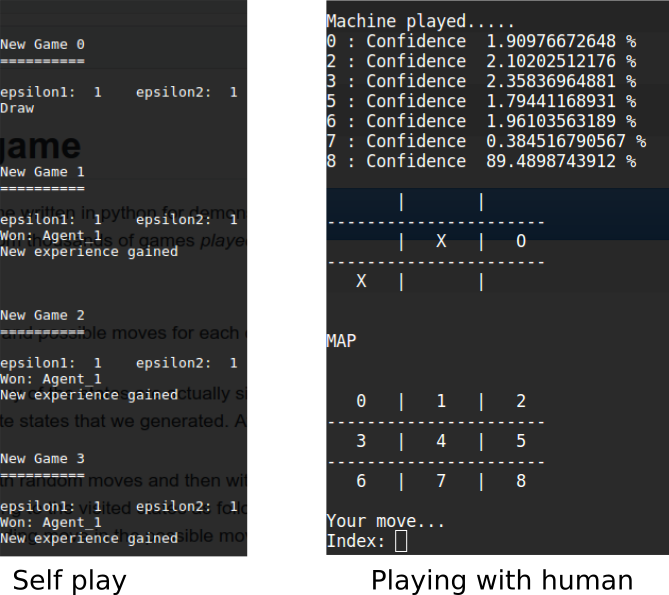
You can copy the following code and run it in python by yourself. It will first train itself with self-play and then start the human play session and wait for your input. Both the code and a trained experience.dat file can be found in my github repository.
import random
import collections
import os
def next_level(statesa, statesb, move):
for i in range(len(statesa)):
for j in range(9):
ns = []
if statesa[i][j]==0:
ns = list(statesa[i])
ns[j] = move
statesb.append(ns)
def flip_vertical(state):
f_state = list(state)
f_state[2] = state [0]
f_state[5] = state [3]
f_state[8] = state [6]
f_state[0] = state [2]
f_state[3] = state [5]
f_state[6] = state [8]
return f_state
def rotate_right(state):
r_state = list(state)
r_state[0] = state[6]
r_state[2] = state[0]
r_state[8] = state[2]
r_state[6] = state[8]
r_state[1] = state[3]
r_state[5] = state[1]
r_state[7] = state[5]
r_state[3] = state[7]
return r_state
def inverse_transform_state(state, rotate_right, flip):
rotate_right = 4 - rotate_right
st = list(state)
while rotate_right > 0:
rotate_right = rotate_right - 1
st = rotate_right(st)
if flip == 1:
st = flip_vertical(st)
return st
def inverse_transform_action(action, rotate_right, flip):
rotate_right = 4 - rotate_right
while rotate_right > 0:
rotate_right = rotate_right - 1
if action == 1:
action = 5
elif action == 5:
action = 7
elif action == 7:
action = 3
elif action == 3:
action = 1
elif action == 0:
action = 2
elif action == 2:
action = 8
elif action == 8:
action = 6
elif action == 6:
action = 0
if flip == 1:
if action == 0:
action = 2
elif action == 3:
action = 5
elif action == 6:
action = 8
elif action == 2:
action = 0
elif action == 5:
action = 3
elif action == 8:
action = 6
return action
def forward_transform_action(action, rotate_right, flip):
if flip == 1:
if action == 0:
action = 2
elif action == 3:
action = 5
elif action == 6:
action = 8
elif action == 2:
action = 0
elif action == 5:
action = 3
elif action == 8:
action = 6
while rotate_right > 0:
rotate_right = rotate_right - 1
if action == 1:
action = 5
elif action == 5:
action = 7
elif action == 7:
action = 3
elif action == 3:
action = 1
elif action == 0:
action = 2
elif action == 2:
action = 8
elif action == 8:
action = 6
elif action == 6:
action = 0
return action
def delete_duplicates(states):
indices = []
for i in range(len(states) - 1):
temp = list(states[i])
for j in range(i+1, len(states)):
match, rot, flip = isequal(states[j], temp)
if(match): # All orientation of temp will be checked here
indices.append(j)
else:
continue
indices = list(set(indices))
unique_states = []
for k in range(len(states)):
if(bool(indices.count(k))):
continue
else:
unique_states.append(states[k])
return unique_states
def random_list(indexList): #TODO: Check this. Setting zero actions also
rand_list = []
for i in range(10):
r = random.randint(0,8)
if indexList.count(r) == 1:
rand_list.append(r)
else:
i = i-1
return rand_list
def set_random_moves(states):
states_action = []
for i in range(len(states)):
actions = []
for j in range(len(states[i])):
if states[i][j] == 0:
actions.append(j)
actions.append(j)
sa = [states[i] , actions]
states_action.append(sa)
print(i)
return states_action
def check_win(state):
if state[0] == 1 and state[1] == 1 and state[2] == 1:
return 1
if state[3] == 1 and state[4] == 1 and state[5] == 1:
return 1
if state[6] == 1 and state[7] == 1 and state[8] == 1:
return 1
if state[0] == 1 and state[3] == 1 and state[6] == 1:
return 1
if state[1] == 1 and state[4] == 1 and state[7] == 1:
return 1
if state[2] == 1 and state[5] == 1 and state[8] == 1:
return 1
if state[0] == 1 and state[4] == 1 and state[8] == 1:
return 1
if state[2] == 1 and state[4] == 1 and state[6] == 1:
return 1
if state[0] == 2 and state[1] == 2 and state[2] == 2:
return 2
if state[3] == 2 and state[4] == 2 and state[5] == 2:
return 2
if state[6] == 2 and state[7] == 2 and state[8] == 2:
return 2
if state[0] == 2 and state[3] == 2 and state[6] == 2:
return 2
if state[1] == 2 and state[4] == 2 and state[7] == 2:
return 2
if state[2] == 2 and state[5] == 2 and state[8] == 2:
return 2
if state[0] == 2 and state[4] == 2 and state[8] == 2:
return 2
if state[2] == 2 and state[4] == 2 and state[6] == 2:
return 2
return 0
def isequal(state,present_state):
rotation = 0
flip = 0
temp = list(present_state)
matched = True
for i in range(len(state)):
if state[i] != temp[i]:
matched = False
break
if(matched ==True):
return True, rotation, flip
temp = rotate_right(temp) #1st rotation
rotation = rotation +1
matched = True
for i in range(len(state)):
if state[i] != temp[i]:
matched = False
break
if(matched ==True):
return True, rotation, flip
temp = rotate_right(temp) #2nd rotation
rotation = rotation +1
matched = True
for i in range(len(state)):
if state[i] != temp[i]:
matched = False
break
if(matched ==True):
return True, rotation, flip
temp = rotate_right(temp) #3rd rotation
rotation = rotation +1
matched = True
for i in range(len(state)):
if state[i] != temp[i]:
matched = False
break
if(matched ==True):
return True, rotation, flip
temp = list(present_state)
rotation = 0
temp = flip_vertical(temp) #Flip
flip = flip + 1
matched = True
for i in range(len(state)):
if state[i] != temp[i]:
matched = False
break
if(matched ==True):
return True, rotation, flip
temp = rotate_right(temp) #1st rotation
rotation = rotation +1
matched = True
for i in range(len(state)):
if state[i] != temp[i]:
matched = False
break
if(matched ==True):
return True, rotation, flip
temp = rotate_right(temp) #2nd rotation
rotation = rotation +1
matched = True
for i in range(len(state)):
if state[i] != temp[i]:
matched = False
break
if(matched ==True):
return True, rotation, flip
temp = rotate_right(temp) #3rd rotation
rotation = rotation +1
matched = True
for i in range(len(state)):
if state[i] != temp[i]:
matched = False
break
if(matched ==True):
return True, rotation, flip
return False, rotation, flip
def display(game_state):
gs = list(game_state)
for i in range(len(gs)):
if gs[i] == 1:
gs[i] = "X"
if gs[i] == 2:
gs[i] = "O"
if gs[i] == 0:
gs[i] = " "
line1 = gs[0:3]
line2 = gs[3:6]
line3 = gs[6:9]
print " ",line1[0]," | ",line1[1]," | ", line1[2]
print "----------------------"
print " ",line2[0]," | ",line2[1]," | ", line2[2]
print "----------------------"
print " ",line3[0]," | ",line3[1]," | ", line3[2]
print "\n\nMAP\n\n"
print " ","0"," | ","1"," | ", "2"
print "----------------------"
print " ","3"," | ","4"," | ", "5"
print "----------------------"
print " ","6"," | ","7"," | ", "8"
def learn(game_state, win, states):
rew = int((10 - len(game_state))/2) # More addition for shorter game length
for i in range(len(game_state)-1):
action_actual = (game_state[i][1])[0]
for j in range(len(states)):
match, rot, flip = isequal(states[j][0],game_state[i][0])
if match:
action_internal = forward_transform_action(action_actual, rot, flip)
if(win == 1):
if((i+1) % 2 != 0):
loop = rew + int((9 - (len(game_state) - i - 2))/2)
# print "rew: " , rew
# print "Bonus: ", int((9 - (len(game_state) - i - 2))/2)
# sss = input("sss ")
for n in range(loop):
states[j][1].append(action_internal)
if((states[j][0])[action_internal] != 0):
print "Wrong insertion"
print states[j][0]
print action_actual
print rot, ' ', flip
print action_internal
sys.exit()
else:
loop = rew + int((9 - (len(game_state) - i - 2))/2)
for n in range(loop):
if(states[j][1].count(action_internal) > 1):
states[j][1].remove(action_internal)
if(win == 2):
if((i+1) % 2 != 0):
loop = rew + int((9 - (len(game_state) - i - 2))/2)
for n in range(loop):
if(states[j][1].count(action_internal) > 1):
states[j][1].remove(action_internal)
else:
loop = rew + int((9 - (len(game_state) - i - 2))/2)
for n in range(loop):
states[j][1].append(action_internal)
if((states[j][0])[action_internal] != 0):
print "Wrong insertion"
print states[j][0]
print action_actual
print rot, ' ', flip
print action_internal
sys.exit()
print "New experience gained"
def action_epsilon_greedy(actions, epsilon):
a = list(set(actions))
if len(a) == 1:
return a[0]
best_action = max(set(actions), key=actions.count)
random_action = random.choice(a)
if(random.random() > epsilon):
return best_action
else:
return random_action
def start_self_play(states, iteration):
for i in range(iteration):
if i < iteration * 0.25:
#random game
epsilon1 = 1
epsilon2 = 1
elif i < iteration * 0.5:
#Random strategy with best opponent
epsilon1 = 1
epsilon2 = 0
elif i < iteration * 0.75:
#Best strategy With random opponent
epsilon1 = 0
epsilon2 = 1
elif i < iteration * 1.0:
#mixed strategy
epsilon1 = 0.3
epsilon2 = 0.3
# epsilon1 = 1
# epsilon2 = 1
game_state = [[[0,0,0,0,0,0,0,0,0],[]]]
win = 0
print "\n\n\nNew Game "+ str(i)
print "=========="
print ""
print "epsilon1: ",epsilon1," epsilon2: ",epsilon2
while True:
# print "\n\nSearching move 1...\n"
# print "Game state: ", game_state[-1][0]
found = False
for s in states:
match, rot, flip = isequal(s[0],game_state[-1][0])
if match:
# print "Game state: ", game_state[-1][0]
# print "Intr state found: ", s[0]
move1_internal = action_epsilon_greedy(s[1], epsilon1)
# print "Intr move : ", move1_internal
# print rot,' ', flip
move1_actual = inverse_transform_action(move1_internal, rot, flip)
# print "Actl move : ", move1_actual
game_state[-1][1].append(move1_actual)
new_state = list(game_state[-1][0])
if(new_state[move1_actual] != 0 ):
print "Wrong move"
sys.exit()
new_state[move1_actual] = 1
# print "New State : ", new_state
# k = input("Found: ")
game_state.append([new_state, []])
# display(game_state[-1][0])
found = True
break
if(found == False):
print "Game error: Unable to find state"
save_experience(states, 'log.dat')
sys.exit()
found = False
win = check_win(game_state[-1][0])
if win != 0:
print "Won: Agent_" + str(win)
learn(game_state, win, states)
break
if sum(game_state[-1][0]) == 13:
print "Draw"
break
# print "\n\nSearching move 2...\n"
# print "Game state: ", game_state[-1][0]
# k = input("Found: ")
for s in states:
match, rot, flip = isequal(s[0],game_state[-1][0])
if match:
# print "Game state: ", game_state[-1][0]
move2_internal = action_epsilon_greedy(s[1], epsilon2)
move2_actual = inverse_transform_action(move2_internal, rot, flip)
game_state[-1][1].append(move2_actual)
new_state = list(game_state[-1][0])
if(new_state[move2_actual] != 0 ):
print "Wrong move"
sys.exit()
new_state[move2_actual] = 2
game_state.append([new_state, []])
# print "Intr state: ", s[0]
# print "Intr move : ", move2_internal
# print rot,' ', flip
# print "Actl move : ", move2_actual
# print "New State : ", new_state
# k = input("Found: ")
# display(game_state[-1][0])
found = True
break
if(found == False):
print "Game error: Unable to find state"
save_experience(states, 'log.dat')
sys.exit()
win = check_win(game_state[-1][0])
if win != 0:
print "Won: Agent_" + str(win)
learn(game_state, win, states)
break
def start_human_play(states):
for i in range(1):
game_state = [[[0,0,0,0,0,0,0,0,0],[]]]
win = 0
print "\n\n\nNew Game "+ str(i)
print "==========\n\n"
print ""
while True:
print "Machine played....."
for s in states:
match, rot, flip = isequal(s[0],game_state[-1][0])
if match:
# print "internal state: ", s[0]
move1_internal = 0
count = 0
m = list(set(s[1]))
# print "moves: ", s[1]
for move in m:
print move, ": Confidence ",float(s[1].count(move))/float(len(s[1])) * 100 ,"%"
if(s[1].count(move) > count):
move1_internal = move
count = s[1].count(move)
move1_actual = inverse_transform_action(move1_internal, rot, flip)
# print "Picked internal: ", move1_internal
# print "Picked Actual : ", move1_actual
game_state[-1][1].append(move1_actual)
new_state = list(game_state[-1][0])
new_state[move1_actual] = 1
game_state.append([new_state, []])
# internal_state = list(s[0])
# internal_state[move1_internal] = 1
# print "internal state: ", internal_state
break
print ""
display(game_state[-1][0])
print ""
win = check_win(game_state[-1][0])
if win != 0:
print "MACHINE WON"
break
if sum(game_state[-1][0]) == 13:
print "GAME DRAW"
break
new_state = list(game_state[-1][0])
while (True):
print "Your move..."
move2 = int(input("Index: "))
if(new_state[move2] !=0):
continue
new_state[move2] = 2
break
game_state.append([new_state, []])
win = check_win(game_state[-1][0])
if win != 0:
print "YOU WON !"
break
display(game_state[-1][0])
print ""
if sum(game_state[-1][0]) == 13:
print "GAME DRAW"
break
def save_experience(states, file):
with open(file, 'w') as exp:
for s in states:
dat = [str(x) for x in s[0]]
dat = ','.join(dat)
exp.write(dat+'\n')
dat = [str(x) for x in s[1]]
dat = ','.join(dat)
exp.write(dat+'\n')
def load_experience(file):
states = []
with open(file, 'r') as exp:
lines = [x.strip() for x in exp.readlines()]
lines = [x.split(',') for x in lines]
dat = []
for e in lines:
temp = [int(x) for x in e]
dat.append(temp)
states = []
for i in range(0,len(dat),2):
states.append([dat[i], dat[i+1]])
return states
##############################################################
states1 = [[1,0,0,0,0,0,0,0,0], [0,1,0,0,0,0,0,0,0], [0,0,0,0,1,0,0,0,0]]
states2 = []
states3 = []
states4 = []
states5 = []
states6 = []
states7 = []
states8 = []
states9 = []
try:
print "Trying to load experience.dat.."
states = load_experience('experience.dat')
except:
print "STATUS: experience.dat not found."
print "Generating states..."
next_level(states1,states2,2)
print "1st level state reduction.."
states2 = delete_duplicates(states2)
next_level(states2,states3,1)
print "2nd level state reduction.."
states3 = delete_duplicates(states3)
next_level(states3,states4,2)
print "3rd level state reduction.."
states4 = delete_duplicates(states4)
next_level(states4,states5,1)
print "4th level state reduction.."
states5 = delete_duplicates(states5)
next_level(states5,states6,2)
print "5th level state reduction.."
states6 = delete_duplicates(states6)
next_level(states6,states7,1)
print "6th level state reduction.."
states7 = delete_duplicates(states7)
next_level(states7,states8,2)
print "7th level state reduction.."
states8 = delete_duplicates(states8)
next_level(states8,states9,1)
print "8th level state reduction.."
states9 = delete_duplicates(states9)
states = states1 + states2 + states3 + states4 + states5 + states6 + states7 + states8 + states8
states = set_random_moves(states)
states = states + [[[0,0,0,0,0,0,0,0,0],[0,0,1,1,4,4]]]
save_experience(states, 'zero_experience.dat')
print "No of state: ", len(states)
####################################################################################################
start_self_play(states, 10000) #comment this line if experience.dat is generated
save_experience(states, 'experience.dat') #comment this line if experience.dat is generated
start_human_play(states)
References:
[1] Book: Reinforcement Leaning an Introduction by Sutton and Barto.